AI Chain Testing
Promptmanship: process, concepts, activities, and patterns
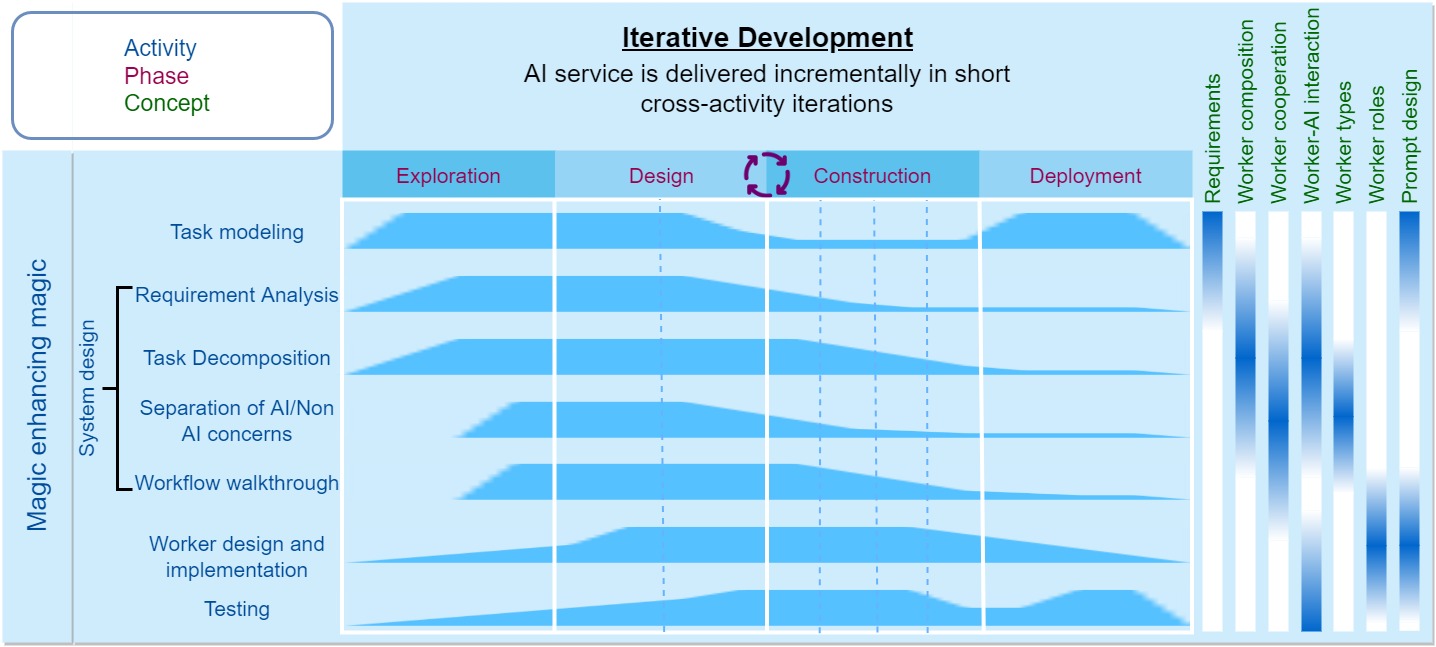
AI chain testing involves running an AI chain and its component workers (prompts), evaluating the running results, and debugging and fixing unexpected behaviors. Similar to traditional testing, we can perform unit tests for each worker, integration (interface) tests for cooperating workers, and system tests for the entire AI chain. Our IDE's Block view supports all three levels of testing.
Since the behavior of foundation models is un-designed but emergent, testing methods based on verifying design and construction correctness are no longer applicable. AI chain testing and prompt testing are more of an experimental process to gain mechanical sympathy for the model and to find effective prompts to interact with the model. This process begins in the exploration stage and continues throughout the rapid prototyping process of AI chain. In our IDE, users can experiment prompts in the Exploration view, and test and debug a worker's prompt in the Block view.
Due to the emergent behavior of foundation models and the flexibility of natural language, it is impossible to achieve ``comprehensive'' testing in the traditional sense, no matter how much effort is put into it, as evidenced by unexpected prompt injection and jail-breaking in ChatGPT. This highlights the importance of user testing, such as AI test kitchen which leverage crowd intelligence to test and improve emerging AI technology. We plan to support crowd testing of AI chains in our AI chain marketplace.
Exploring the behavior of foundation models requires creativity, and even experts may have limitations in their personal experience and knowledge, leading to blind spots. Large language models can be utilized to supplement the creativity of individuals. For example, Ribeiro and Lundberg proposed adaptive testing and debugging of NLP models, using the LLM to generate additional test cases from seed test cases given by humans. Not only can humans gain inspiration from the LLM-generated test cases, but they can also more comprehensively test the AI behavior. As another way, we can give the current prompt and the actual versus expected prompt outputs to the LLM and request it to revise the prompt to match the actual output to the expected one.